
目次
セミナー概要
自社内でサーバーやネットワーク機器などを保有するオンプレとは対照に、外部で運用するクラウドにおける非機能要件の設計を学ぶセミナー「クラウド非機能要件」がBFT道場で開催された。クラウドにおける可用性設計やセキュリティなどについて、IBMのDistinguished Engineerの経歴を持つ山下克司氏が解説する。なお、本セミナーは「クラウド・アーキテクチャ」をテーマにして行われた全4回の最終回である。

信頼性と可用性の基礎
非機能要件の基礎知識
クラウドの非機能要件として考えるべき項目に、耐障害性や回復性を表す「信頼性と可用性」、システムの容量とコストを考慮する「性能と容量」、監視や変更管理を行う「運用性」、システムを脅威から守る「セキュリティ」、移行要求に対応する「移行性」がある。

これらの非機能要件を検討する際に必要なのが、機能要件の定義づけである。クライアントが必要とする機能要件を軸に非機能要件を検討していくため、これがないと非機能要件を定義することはできない。
また、非機能要求グレードがテンプレートとして公開されているが、これを設計の根拠としてはいけない。これはあくまで目安としての数字であり、過剰な要求を追求し余計なコストがかかることに繋がりかねない。
例えば、作業状況を入力するプロジェクト管理システムがあったとする。その場合は、その入力作業を完了するためにレスポンスタイムが何秒以内だとユーザーがレスポンスを待って業務を完了することができるかを考える必要がある。下図の場合、業務完了率90%ラインを目標とすると、それが保てるレスポンスタイムが必要とされるのであり、過剰に早いレスポンスタイムを追求することは不必要なのである。
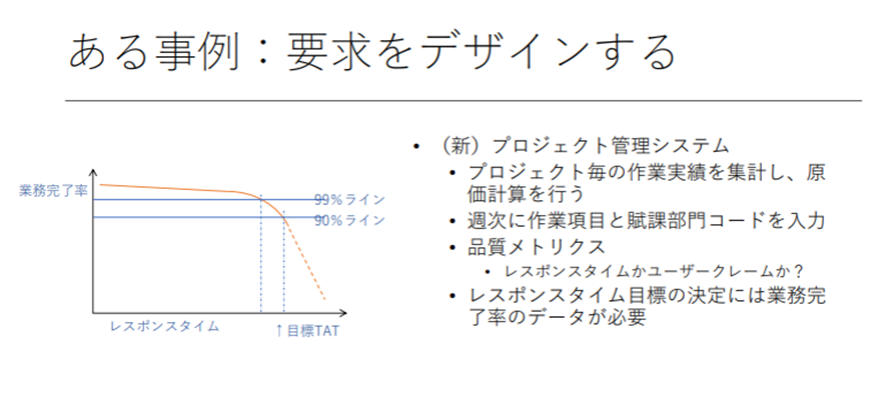
このように、クラウド非機能要件の検討は、機能要件の決定と非機能要求グレードを根拠としないということが前提になる。
信頼性と可用性
可用性は、MTBF(平均連続稼働時間)とMTTR(平均障害対応時間)の合計のMTBFの割合のことをいう。
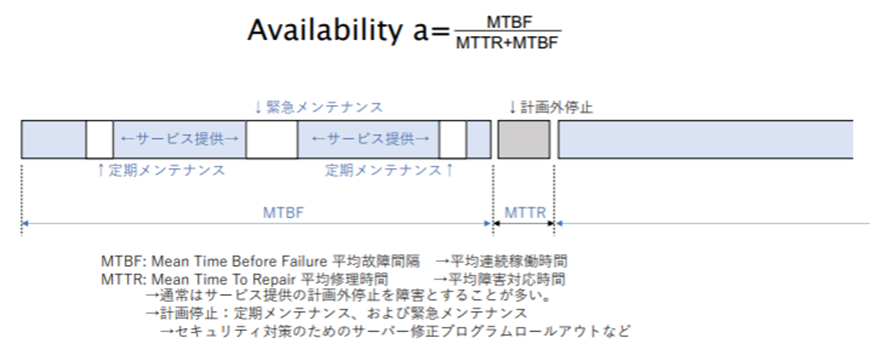
可用性は可用性SLA(Service Level Agreement)として、ユーザーとクラウド事業者との間でサービス提供や品質などの契約合意を結ぶ際に使用される。この可用性SLAは、計画外停止の際の返金条件を示すことが主たる目的である。
ここで気を付けなければならないのが、可用性計算と信頼性計算は異なるということである。
下図のように、MTBF35年のシステムのMTTRを8時間として計算を行うと可用性99.997%となるが、5年間運用した場合の8時間停止の確率は13%となる。8時間の停止は当然いつ起こるか分からないためこのような確率になるのである。信頼性計算の数字により、可用性99.997%の印象が大きく変わってくる。

このように、可用性を検討する際には信頼性が重要な指針になる。可用性を過信してはならず、障害は起こるものとして備えておく必要がある。
また注意しておきたいのが、証憑(しょうひょう)条件の存在である。システムが停止した際、ユーザー側はシステムが停止していたことを証明する必要がある。そのため、ログなどで証明できるようにあらかじめ備えておく必要がある。
さらに、多くの障害は予測されたルールとは異なるところで発生することも忘れてはいけない。想定外の確率も考慮しなければ正確な数字が割り出せない。
このように信頼性と可用性を考慮するためにはさまざまなパターンを想定して合意を行い、備えておく必要がある。
高可用性設計の方針
障害が発生した際に問題となるのは、Timeoutするセッションにどれだけユーザーのデータが残っているかである。このTimeoutするセッションをできる限り最小にするため、セッションがステートをもたないように設計をするのがベストである。例えば、セッションをクライアント接続のクッキーに埋め込んだり、サーバーのバックアップを取得したりなどである。
また、アプリケーションサービスの稼働がデータベースなどの内臓データに依存している場合、サーバーに障害が発生するとデータの部分が消えてしまい自動再起動プロセスだけでは再起動しないという問題が生じる。これはクラウドのサーバーイメージレポジトリから再現できる範囲が、アプリケーション、ミドルウェア、OSに限られるからである。
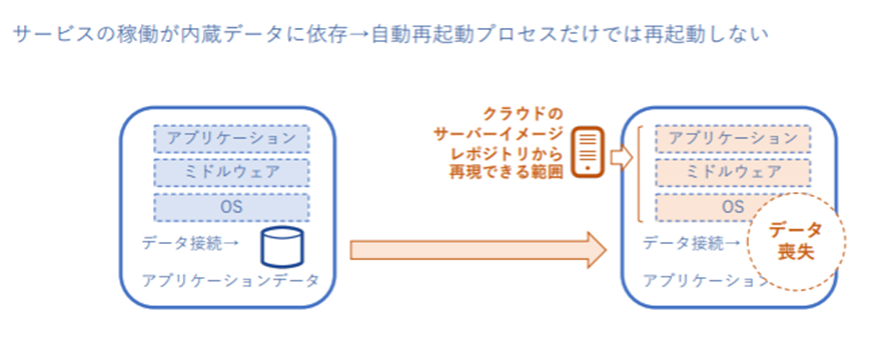
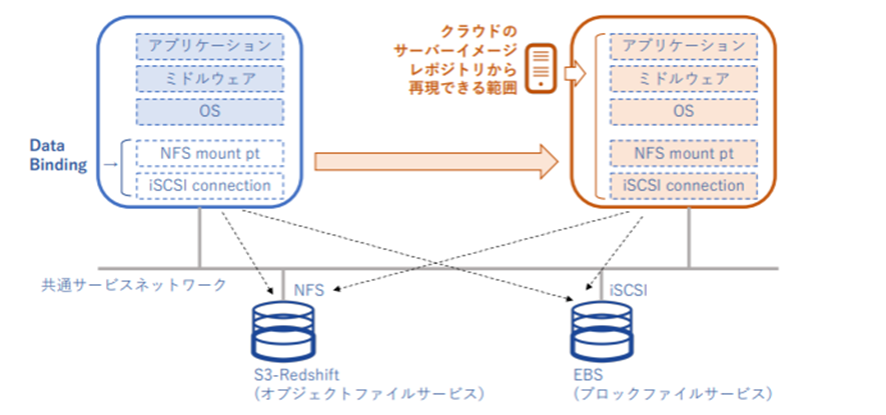
そのため下図のように、データはアプリケーションサービスと分離しておくべきである。
また、併せてデータのバックアップも取得しておくことが必要である。
災害対策とサイトプラン
災害対策の大きな指針として、目標復旧時点を表すRPO(Recovery Point Objective)と目標復旧時間を表すRTO(Recovery Time Objective)がある。
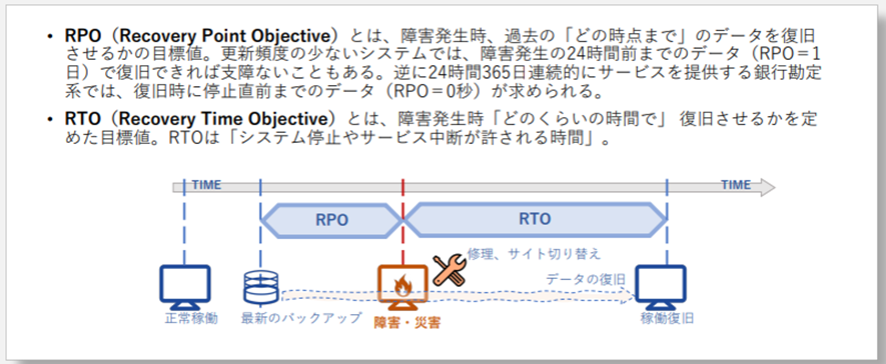
RPOはデータに関連性があるトランザクションの場合は厳しい要件が要求される。銀行勘定系ではRPOが0秒、すなわち障害により停止する直前までのデータ復旧が求められる場合もある。RPOを0秒とする場合は、障害発生時点で処理が開始されているが完了していないデータは拾わず、処理が完了しているものはすべて拾う必要がある。
そして災害対策のために、こうしたRPOやRTOを考慮したサイトプランを構築する必要がある。
下図はAWS(Amazon Web Services)で災害対策を考慮したデータ配置のサイトプランの例である。東京リージョンでは異なるアベイラビリティゾーン(AZ)にストレージレプリケーションを配置しておき、アベイラビリティゾーンでの障害に備える。さらにシドニーリージョンに監視、自動化コンソールやバックアップデータや障害復旧に必要なアプリケーションリポジトリなどを配置しておくことで、東京リージョンでの障害に備える。
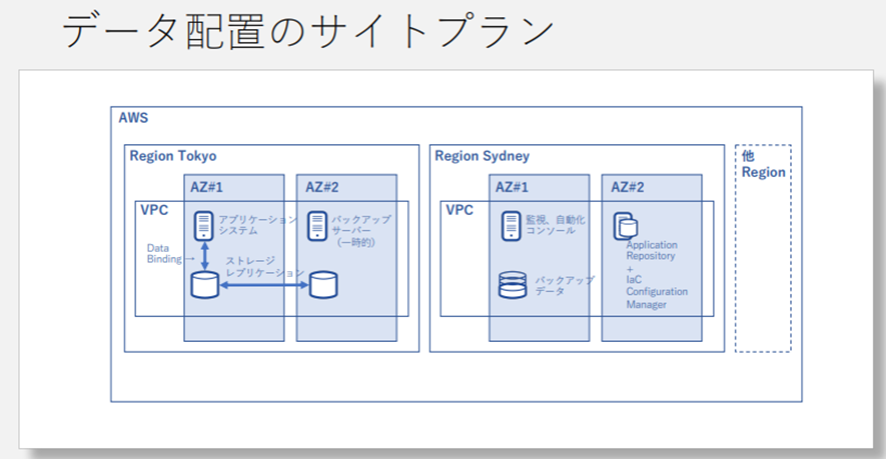
こうしたプランをたてて自動的に障害復旧が行われる仕組みを構築し、RPOとRTOを計算する必要がある。
パフォーマンスとキャパシティ
クラウドは柔軟なパフォーマンスが得られる代わりに、SLAでのパフォーマンスが得られなかったことを証明することが難しいという問題がある。また返金されたとしてもわずかな金額にすぎない。
そのため、処理容量は変動することを前提としてパフォーマンスモニターを行い、管理できる仕組みをもつことが重要である。例えばモニタリングアラートからチケットを発行し変動に対応することや、変動が予測される場合は事前に容量増強のスケジューリングを行うといった対応をしておくことも必要である。
また、オンプレミスの場合はサーバーやネットワークなどが占有されており安定した性能が得られるが、クラウドの場合はクラウドソフトウェアによって実現されているテナントであるために、共有リソースの影響を受けやすい。
これはパフォーマンステストでも大きな差がでてくる。オンプレミスの場合は負荷の限界値を把握してパフォーマンスバジェット(パフォーマンスに影響を与える指標の上限)を超えた際にアラートとチューニングが行えるような仕組みが整っていればよい。しかし、クラウドの場合はクラウドパフォーマンスが一定ではないために、アプリケーションパフォーマンスの負荷をテストしても一定の結果が得られない。そのため、クラウドパフォーマンスとアプリケーションパフォーマンスの『相関関係』ととらえてテストを行う必要がある。
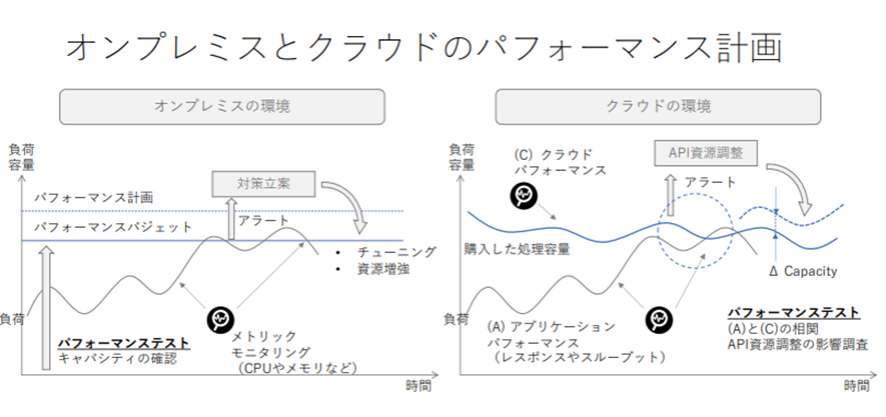
またオンプレミスの場合は資源増強に時間を要するが、クラウドの場合は数分で資源調整が可能であることから、パフォーマンスが低下した際にあとどの程度の資源が必要であるかを把握しておくことも重要である。
また、パフォーマンスが低下した際即座に状態の把握が行えるように、あらかじめCrisis Toolsを入れておいたり、調査用のコマンドを準備しておいたりといったことも必要である。

コンテナのセキュリティ
クラウドであるかコンテナであるかに関わらず、セキュリティの原則は以下のとおりである。
・最小権限
・多少防御
・攻撃対象領域の縮小
・影響範囲の制限
・職務分掌
これらのセキュリティの原則を考慮するために、AWSでいうとAmazon Inspectorなどのツールを活用することが重要だ。
また脆弱性の情報を知ることも重要である。米国標準技術研究所が運営するNVD(National Vulnerability Database)や共通脆弱性識別子を表すCVE(Common Vulnerabilities and Exposures)などを参照し、システムを脅威から守っていく必要がある。
そしてコンテナ環境には論理的な脅威が必ず存在している。Webアプリケーションに関する脆弱性やリスクなどを研究し、その危険性が最も高いと判断された項目をまとめたセキュリティレポートである「OWASP Top 10」が発表したものとして下図のものがある。

まずコンテナは仮想マシンではなくプロセスとして動いているということを認識しておかなければならない。まるでコンテナが一つのサーバーとしてみえるが、実際には一つのサーバーの一つのOS上でコンテナ環境が動いている。
この構造のために、コンテナの脅威はコンテナネットワーク内部に収まらない。
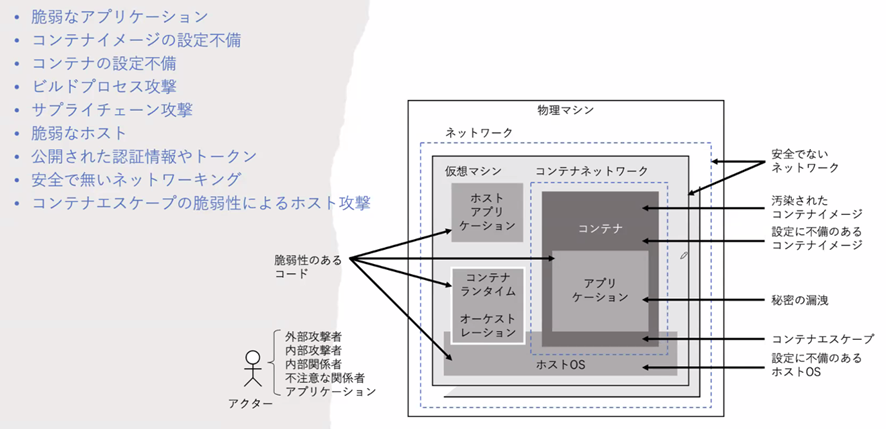
またコンテナは、各コンテナが利用できるシステムリソースを管理するコンテナグループ(cgroup)や、コンテナ独自の名前空間(マウント可能なファイルシステム)を作ることで、コンテナ環境の分離ができるが、ここでも脆弱性が生じる危険性がある。
このようにコンテナ環境は構造上の脆弱性が潜むため、ファイルシステムの管理の徹底や、マウントポイントの変更はログで監視するなどの対策が必要になる。
また、コンテナ管理を自動化・効率化するソフトウェアであるKubernetesにも攻撃ベクタが観測されているため注意が必要である。下図はMicrosoftが提供しているAttack Matrixだが、多くの脆弱性があげられていることが分かる。
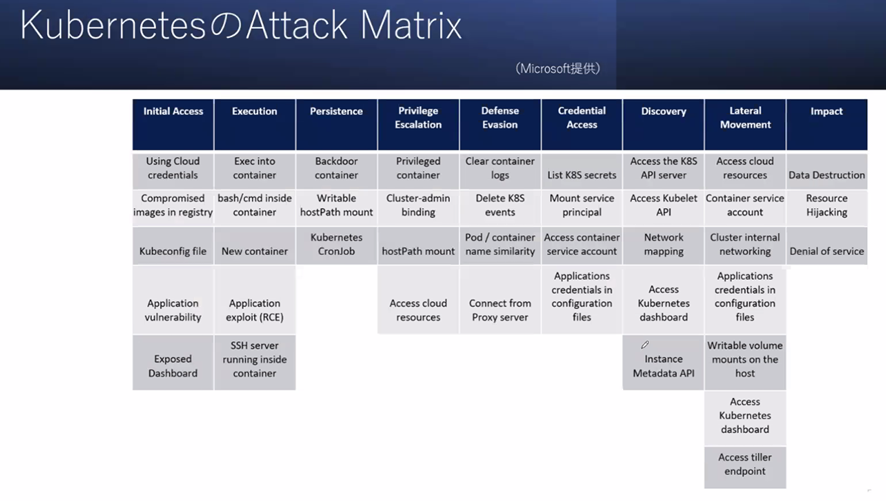
これらの脅威に対して、SELinuxの設定を行ったり、docker-bench-securityでコンテナイメージ自体をセキュアにしたり、Dockerの場合は脆弱性を集中管理するREST APIやコンテナの脆弱性をスキャンするツールを利用したりすることが有効である。
アンケート結果紹介
今回のセミナーに参加した全員の受講者が、「役に立った」「大いに役に立った」と回答した。
さらにセミナーの内容の理解についても、8割近くの受講者が「どちらかというと理解できた」「理解できた」と回答した。
具体的には「非機能要件のポイントと詳細な考え方を見直せた」や「Linuxに関するコマンドやコンテナについても学べ、さらに調査したいと思った」などのコメントがよせられた。
一方で、クラウドを触ったことがない受講者の中には「専門用語が多く難しい」と感じた者もいた。しかしそういった受講者も「実践で理解を確認したい」や「復習することで理解したい」と今後に活かすための前向きなコメントをよせていた。
セミナーを受講して
今回はオンプレミスでも共通する非機能要件の内容ということもあり、理解がしやすかった。概念的な説明だけではなく、どういった内容を検討する必要があるのか、具体的に解説されているのがすごく勉強になった。
非機能要件を意識することは若手のエンジニアでは少ないと思うが、ここを理解しておくでシステムの全体像を把握しやすくなり、自分の行っている作業の目的がしっかりと理解できるようになるのではないかと感じた。
本セミナーは、BFT道場の教育サービスご契約者、受講者であれば誰でも受講できる無料セミナーとして実施した際の内容をレポート化したものだ。BFT道場では現役のインフラエンジニア講師による実践型IT技術研修を提供している。詳しくはBFT道場をご覧いただきたい。

