
セミナー概要
クラウド環境におけるシステム運用・監視は、従来のオンプレミス環境とは異なるアプローチが必要となる。 クラウド環境で運用しているシステムに対して、どのような監視が必要なのかを学ぶセミナー「監視とサービスデスク」がBFT道場で開催された。 クラウド環境とオンプレミス環境での違いも含めた監視についてIBMのDistinguished Engineerの経歴を持つ山下克司氏が解説する。 なお、セミナーは「クラウド・アーキテクチャ」をテーマにして全4回の開催を予定している。今回はその第2回である。

監視の設計
クラウドという技術が発展したことによって、大きく変わったのがシステム運用・監視の部分である。
クラウド環境では、サービスへのアクセスが集中した際にサービスダウンを防ぐためにサーバーの台数を増やすスケールアウトやサーバーの性能を変更するスケールアップ、反対にサーバーの負荷が下がった場合にはコストを抑えるためにサーバーの台数を減らすスケールインなどを迅速に行うことが可能である。また、これらの対応を自動的に行う機能もある。
このようにクラウド環境では、リソースの配置変更や増減などが動的に起こるため監視対象そのものが動的な存在となる。監視対象の動きが動的ということではなく、監視対象そのものが動的であるため、クラウドリソースの上で自分たちのシステム全体がどう動いているのかを正しく監視する必要がある。正しく監視したうえでインシデントや変更点に対応していかなければいけない。
監視には必ず何らかのアスペクト(主題)があり、そのアスペクトごとに監視ツールと監視データがある。複数の監視のアスペクトに対して複数の監視ツールがある場合には、それぞれの監視データを統合した状態で見られないということが問題になりえる。オンプレミス環境ではこうした問題は起こりにくいが、クラウド環境ではサービスがどのサーバーで動いているのかが見えづらいこともあり、問題になりえるのだという。
その問題を起こさないために、データを収集する段階ではデータの発生源を抑えるようなエージェントのセットアップなどを行うことがトレンドになってきていると山下氏は語る。それぞれのエージェントが収集した監視データを整形し一つに統合する。このような設計にすることで、監視のアスペクトごとに必要なデータを抽出して分析や判断といった作業が行えるのだという。
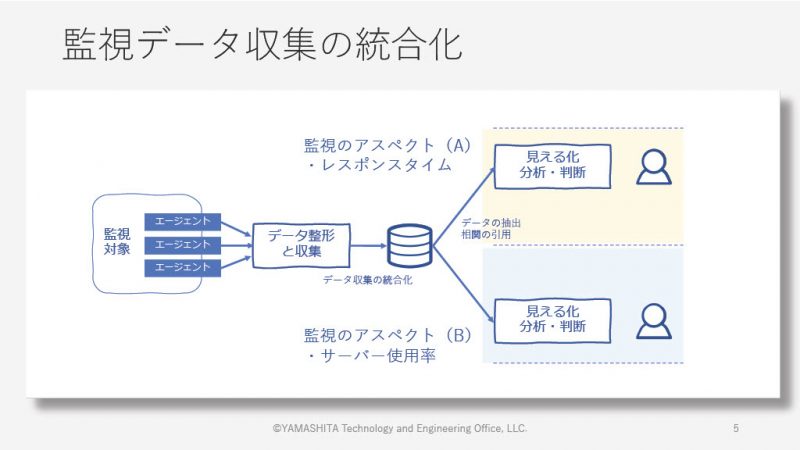
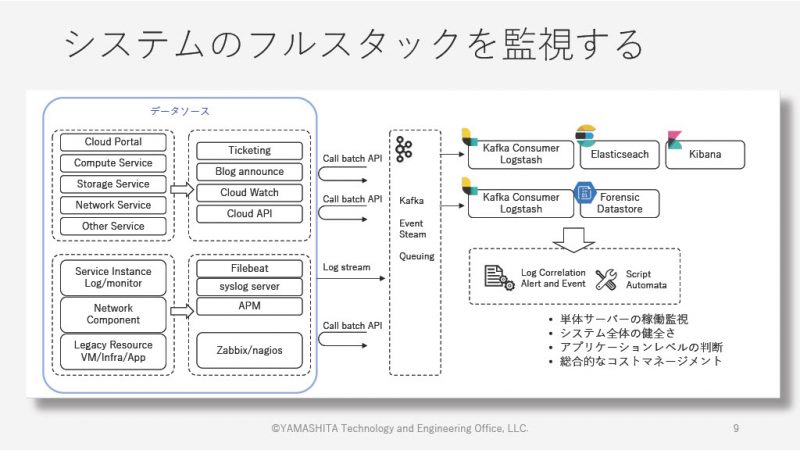
システムのフルスタック監視
単にサービスの監視データを見るだけではシステム全体の監視にはつながらないと山下氏は語る。
クラウド環境では、従来のように自分たちが提供しているサービスを監視するだけではなく、クラウド事業者が提供している共用インフラの部分(ネットワークやゲートウェイなど)の情報も合わせて考えなければ本当の意味でのシステムの監視はできないという。
クラウド環境のシステムは、資源プールからクラウドソフトウェアによって実現されているテナントであり、資源プールの中には複数のテナントが存在している。複数のテナント同士が多くの箇所で干渉しあっており、クラウド環境のシステムにおいては、そうした干渉しあう箇所(共有インフラ)のパフォーマンスメトリクス(活動を定量化し、データを加工した指標 )が全体に大きな影響を与えることになる。
そのため、共用インフラも含めたシステム全体のフルスタック監視を行えるよう、監視メトリクスを設計することが重要だという。
監視メトリクスを正しく設計することで、単体サーバーの稼働監視だけではないシステム全体としての健全さの判断や、APM( Application Performance Management :アプリケーションの性能や応答時間といったパフォーマンスを管理・監視すること)などからパフォーマンスのアプリケーションレベルでの判断といったことができるようにしておくことが望ましいという。
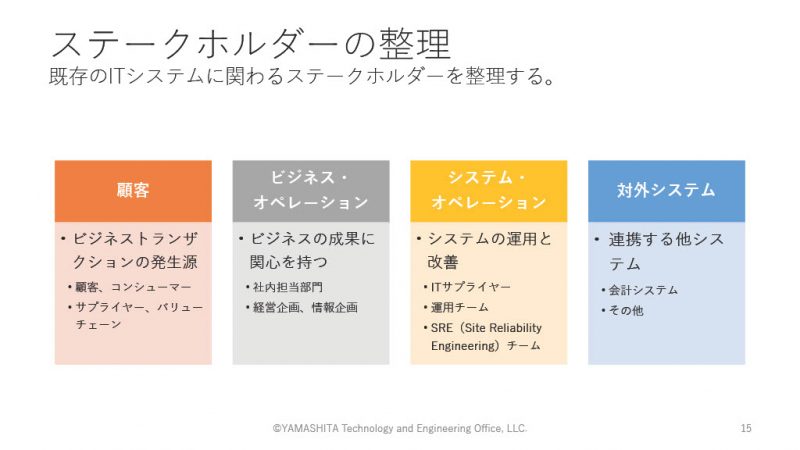
ステークホルダーの整理
メトリクスを正しく設計することは非常に難しく、誰がどのような視点を持っているのかということをしっかり整理しておく、ステークホルダーを整理しておくことが重要だと山下氏は語る。
ステークホルダーは顧客、ビジネス・オペレーション、システム・オペレーション、対外システムの4つに分類される。それぞれのシステムがそれぞれの要求を持っていることを整理して、非機能要件の監視メトリクスを用意する必要があるという。そのためには、要求を正しくデザインする必要があり、どういうシステムの状態が望ましいのか、要求を明確にするためのヒアリングを行うことが必要だという。そして、ヒアリングをもとに自分たちの成果、ビジネスというところに結び付くよう要求をデザインしなければならないという。
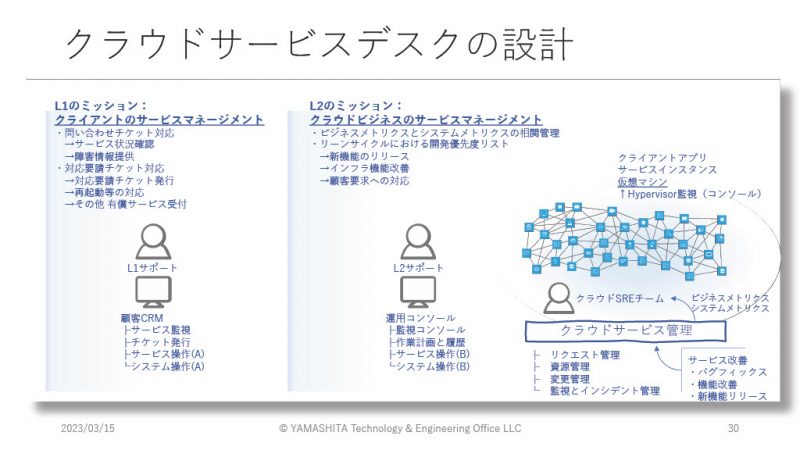
クラウドサービスデスクの設計
クラウドのサービスデスクは大きく3層に分かれている。L1(クライアントのサービスマネージメント)、L2(クラウドビジネスのサービスマネージメント)、L3(クラウドサービス管理)の3層で構成されており、最終的な実運用はL2とL3の連携で行われている。クラウドのサービスデスクの設計で非常に重要なのがL1とL2のミッションの分離である。L1のミッションはクライアントに対するサービスマネージメントであり、L2のミッションはクラウドビジネスのサービスマネージメントである。従来のサービスデスクでは、L1が簡単なミッションを担当し、L1で解決しきれないものをL2が担当するという形式になっていたが、クラウドのサービスデスクではL1とL2で完全に視点が異なるため、クラウドサービスデスクを利用する際はその点に注意が必要だ。
また、以前にAWS(Amazon Web Service:Amazonが提供するクラウドサービス)の東京リージョンで起きた大規模障害(詳細は以下リンクを参照AWSの大規模障害、原因はネットワークデバイス 新プロトコル処理に潜在的なバグ – ITmedia NEWS )のようなクラウドサイドの障害は、クラウドを利用している側では対処できない。そのため、クラウドのサポートとコミュニケーションをとり、情報公開を相互に行うことが重要であるという。障害時に検知したメトリックやシンプトムを公開し、情報共有を行ったうえで、メトリック監視の強化や対策などを行うことがクラウド環境でシステムを運用する際には求められる。

SREへの変化
高い信頼性や性能を発揮するシステムインフラを実現し、改善していくための新しいアプローチの一つとして、SRE(Site Reliability Engineering)がある。SREでは、システムやサービスの信頼性を向上させることを重視する。
クラウドにより従来の監視・運用業務が大きく変化したことや、IaC(Infrastructure as Code)によって開発スピードが上がったことなどのように、システム運用は常に変化している。そうしたさまざまな変化に素早く対応し、システムの高い信頼性を保つことがSREには求められる。また、運用管理の自動化の仕組みを自ら設計・構築すること、開発者が利用しやすいメトリクスのポリシーやツールの整備なども必要になってくる。
クラウド環境におけるシステム運用も、監視メトリクスを正しく設計し、システム全体を健全に、そして高い信頼性を保つことが重要である。

アンケート結果紹介
セミナー後のアンケートでは、多くの受講者が「役に立った」と回答してくれた。 具体的に役に立ったところとしては、「SREについて知れた」、「現在のトレンドについて学べた」という意見もあった。 セミナーの内容に関しては、「理解できた」という受講者と「難しかった」という受講者が半々くらいであった。 「知らない専門用語や製品が出てきた部分が難しかった」、「全体的に難しく、完全に理解しきれていない」といった意見がある一方で、「講師(山下さん)の経験や深い知識を聞くことができ役に立った」、「業務の経験と結びつく部分があり理解しやすかった」という意見もあった。 既にクラウド・アーキテクチャの経験がある方にとっては更なる学びの場、まだ経験のない方にとってはクラウド・アーキテクチャについて理解するきっかけの場として本セミナーを活用していただければ幸いである。
セミナーを受講して
セミナーは、聞きなじみのない専門用語が多かったこともあり、一度で全ての内容を理解するのはなかなか難しいと感じた。一方で、クラウド環境でのシステム運用で注意しなければいけない点については、オンプレミス環境と比較もあり、かなり理解しやすかったと思う。クラウドへの理解を深めつつ、山下氏の経験や最近のトレンドについても聞くことができたため、とても良い経験になったと感じている。
本セミナーは、BFT道場の教育サービスご契約者、受講者であれば誰でも受講できる無料セミナーとして実施した際の内容をレポート化したものだ。
BFT道場では現役のインフラエンジニア講師による実践型IT技術研修を提供している。詳しくはBFT道場をご覧いただきたい。

