
筆者の所属している部署では、AIを用いたシステムの作成に今後取り組んでいきたいと考えています。
今回はその第一歩として、物体検出AIを用いた簡単なシステムを作成し、「AIを用いたシステムの作成」の流れを学びました。
目次
今回の全体像
AIによる物体検出は、画像や動画の中にある物体の位置と種類を特定する技術です。
この技術は、自動運転、セキュリティ、医療などさまざまな分野で応用されており、近年急速に発展しています。
そんな中発表されたYOLO(You Only Look Once)、SSD(Single Shot Detector)、Faster R-CNN(Faster Region-based Convolutional Neural Network)などの高速で高精度な物体検出手法は、画像や動画全体を一度に処理することで、従来の手法よりも効率的に物体検出を行うことができます。
今回は、これらの手法の一つであるYOLOを用いた物体検出AIの作成方法を学ぶため、実際に「麻雀牌が写った画像から麻雀牌を検出するAI」を作成し、その作成手順や検出結果をまとめてみました。
今回の環境構築編では、基本となる物体検出の手法をご紹介するとともに、麻雀牌検出AIの動作環境を構築するところまでお話しします。
AIによる物体検出とは
画像認識と物体検出の違い
画像認識と物体検出は何が違うのでしょうか?言葉自体も似ており、よく混同されがちです。
画像認識とは画像の中に写っているものを機械が検出する技術です。
画像認識はさまざまなカテゴリーに分類することができ、そのカテゴリーの1つとして物体検出があります。
ここで、画像認識の主な4つのカテゴリーについて紹介します。
①物体認識
画像の中に写っているものが何かを特定します。

②物体検出
画像の中のどこに何が写っているか特定します。

③画像分類
画像の中に写っているものの関連性から環境、状況を推定します。
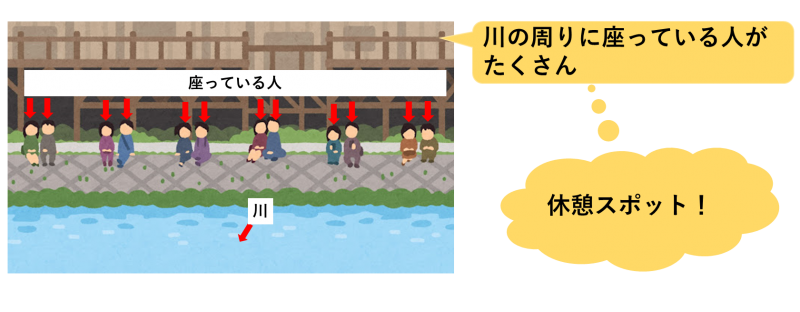
④セグメンテーション
画像の中に写っているものが何かと、写っている領域を検出します。

物体検出の活用事例
物体検出の技術はさまざまなところで活用されています。
ここでは物体検出の主な活用事例をいくつか紹介します。
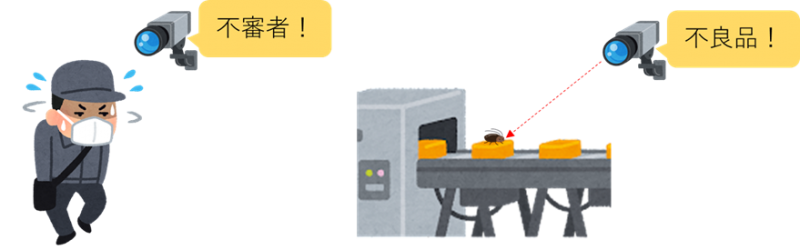
○異常検知
通常の状態とは異なる状態を検知します。防犯カメラに不審者が写った場合通知することや、工場で生産される製品に不良品がないか確認することなどに活用されています。
○自動運転
物体検出技術を用いて信号の色や標識、道路の白線、飛び出してくる人や動物等を検知することで、運転の完全自動化が実現するのではと期待されています。

AIによる物体検出の主な手法
物体検出には複数の手法があります。
ここでは主な物体検出手法について説明します。
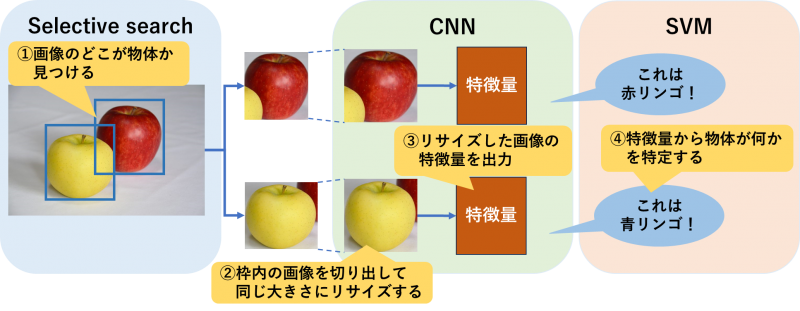
○R-CNN(Region-based Convolutional Neural Network)
R-CNNは「画像のどこに物体があるか?」「画像に写っている物体は何か?」の2段階で物体検出を行う手法です。
R-CNNでは、まずSelective searchと呼ばれる方法で、画像から物体部分を見つけ抽出します。抽出した画像は一定の大きさにリサイズされ、CNNにより特徴量を算出します。
算出した特徴量からSVM(サポートベクターマシン)と呼ばれる分類器により物体の種類を特定します。
この手法では画像に写っている物体の数だけCNNで特徴量を算出する処理を行わなければならず、検出に時間がかかってしまいます。
この欠点を克服するために考えられたのが次のFast R-CNNです。
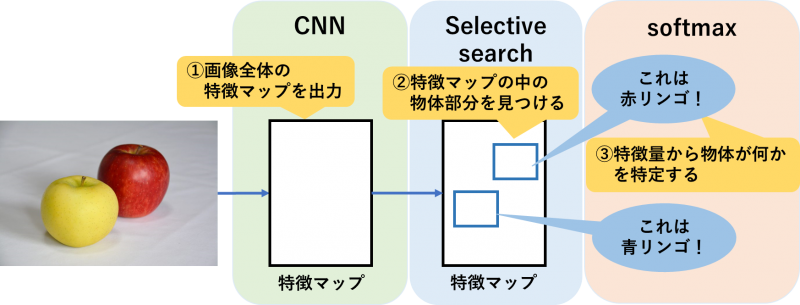
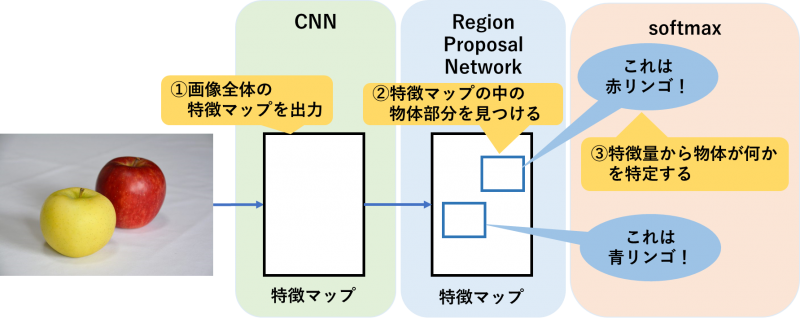
○Fast R-CNN(Fast Region-based Convolutional Neural Network)
Fast R-CNNによる検出はR-CNNと少し流れが異なり、まず画像全体の特徴マップを出力したのち、特徴マップの中で物体部分の特定を行います。これにより、時間を要する特徴量の算出が1回で済むため、R-CNNよりも検出スピードが向上しています。
また、物体が何かを特定する際に用いる分類器も、SVMからsoftmax関数に変更されています。
○Faster R-CNN(Faster Region-based Convolutional Neural Network)
前述のR-CNNとFast R-CNNで物体の位置特定のために用いられているSelective searchは、特定に時間を要するという特徴があります。
Faster R-CNNではFast R-CNNと同じ流れで物体検出を行いますが、物体の位置特定のためにSelective searchではなくRegion Proposal Networkを用いることでさらに検出スピードを向上させています。
○YOLO(You Only Look Once)
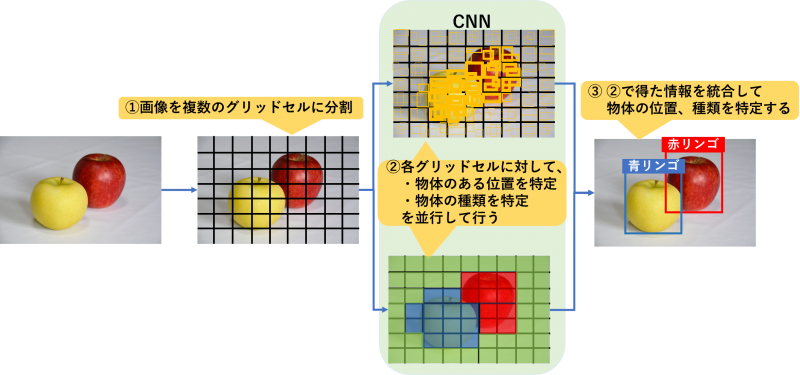
前述の3つの手法では、物体位置の特定を行ってから物体が何かを特定していました。YOLOは、物体位置と物体が何かの特定を同時に実施することで検出スピードを大幅に向上させ、リアルタイムでの物体検出を可能にしました。
以下は検出原理を示す図ですが、詳しくは「YOLOとはどんな手法か」の項目で解説します。
○SSD(Single Shot Detector)
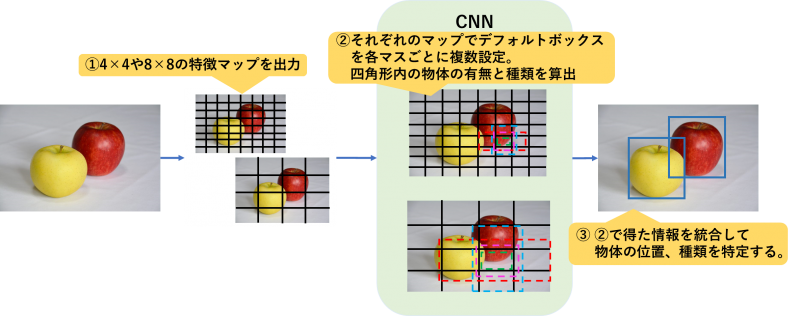
SSDはYOLOと同様に物体位置と物体が何かの特定を同時に実施する検出手法です。
SSDではまず、物体検出を行う画像に対して異なるスケール(4×4や8×8)の特徴マップを出力し、それぞれのマップの各マスにデフォルトボックスと呼ばれるさまざまな大きさ、形の四角形を定義します。
定義した四角形の中の物体の有無、物体の種類を算出し、その結果を統合することで物体検出を行います。
YOLOによる物体検出の仕組み
YOLOとは
YOLOとは、物体検出(object detection)システムのスタンダードな手法の一つで、2015 年にJoseph Redmon氏によって提案されて以来、多くのユーザーに使用されている物体検出モデルです。YOLOは「You Only Look Once」の頭文字をつなげて作られた造語で、「一度見るだけで良い」という意味を持っており、その名前の通りリアルタイムで高精度な物体検出を行うことができます。
次にYOLOとはどのような手法なのか見ていきましょう。
YOLOとはどんな手法か
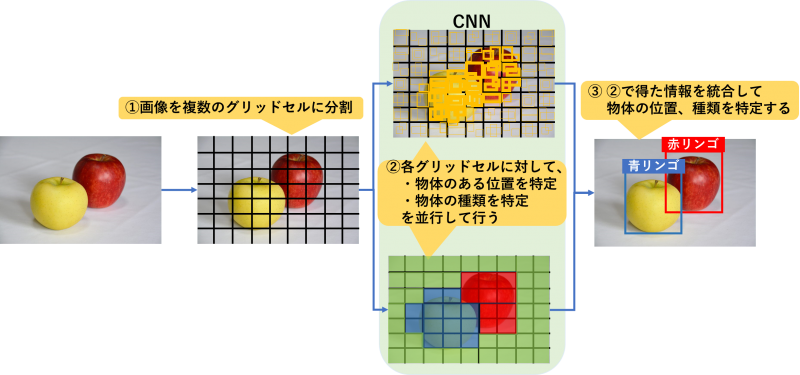
YOLOではまず、物体検出を行う画像をグリッドセルと呼ばれる複数の区画に分割を行います。
その後各グリッドセルに対して「物体の位置特定」と「物体の種類の特定」を同時に行い、それらの結果を統合することで物体検出を行います。
・物体の位置特定
各グリッドセル内にバウンディングボックスと呼ばれるさまざまな大きさの四角形があらかじめ一定数配置されており、その四角形の中に物体があるかどうかを信頼度として数値で算出し、物体の位置を特定します。信頼度はバウンディングボックスの線の太さで表現されています。
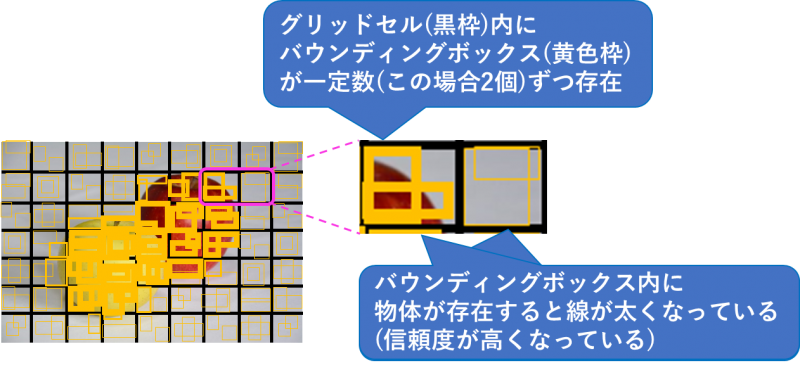
・物体の種類の特定
各グリッドセル内にある物体は何の可能性が高いかを算出します。
物体が写っているセルのみではなくすべてのセルでこちらの処理は行われ、何かしらの結果が出ます。下図の例だと、物体が何も写っていない背景部分においても「バナナ」があるという判定がくだされています。

YOLOを用いた物体検出環境構築
今回構築するシステムの使い方
今回構築したシステムは以下のように使用することを想定して作成しました。
- スマートフォンで麻雀牌を撮影
- スマートフォンから作業用PCへ画像ファイルを送信
- 作業用PCから学習・検出実行用サーバーへ画像ファイルを送信し、YOLOによる物体検出実行を指示
- 学習・検出実行用サーバーから作業用PCへ検出結果を返却
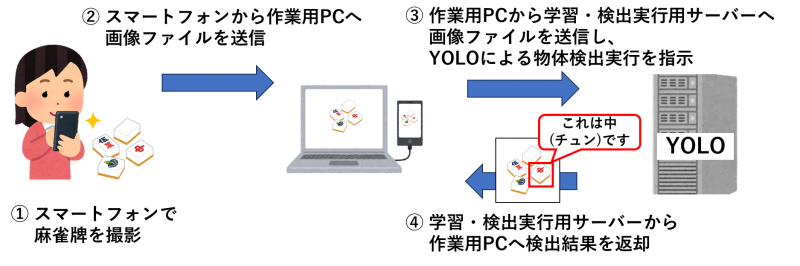
こちらで使用する作業用PCにはあらかじめ以下のツールや環境が導入されています。
| 作業用PC導入済ツール/環境 | 用途 |
|---|---|
| Anacondaによるpython実行用環境 | 教師データ作成 |
| VoTT | アノテーション |
| WinSCP/TeraTerm | サーバーとの接続 |
また、学習・検出実行用サーバーにはGPUが搭載されており、dockerコンテナ環境を整えています。今回使用するサーバーの主なスペックは以下の通りです。
- GPU:NVIDIA 製 GeForce RTX 3080 Ti
- OS:CentOS 8.4
- Docker CE 20.10.10
次は、以下の図を使って、今回構築するシステムの構築から使用開始までの流れを見ていきましょう。
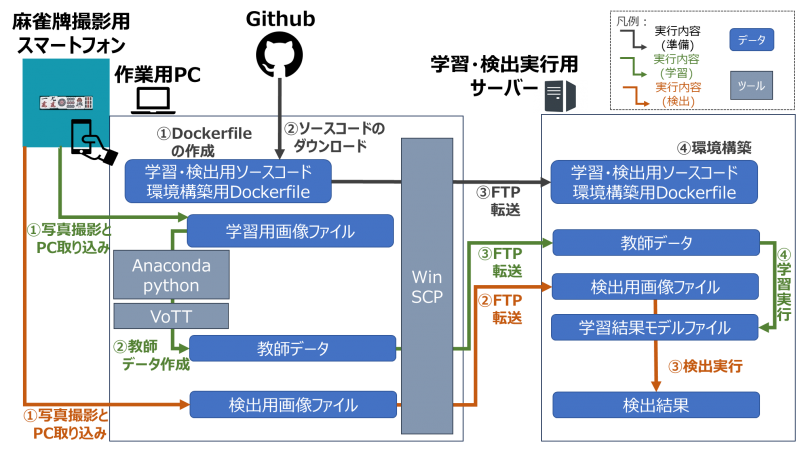
まずは、事前準備を行います。環境構築用のDockerfileを作業用PC上で準備し、学習・検出に使用するソースコードはGithubよりダウンロードします。それをサーバーへFTP転送し、コマンドを実行して環境構築を行います。
次に、学習を実行します。まずはスマートフォン等で撮影した学習用画像ファイルを作業用PCへ取り込み、教師データを作成します。具体的には、データ拡張とアノテーションを行います。(詳しい説明は後編にて行います。) 最後に、作成した教師データを使って、サーバー上で学習を行います。これにより、学習結果のモデルファイルが生成されます。
最後に、検出を実行します。学習と同様に検出用画像ファイルをサーバーへ転送します。その後、学習結果モデルファイルを使用して検出を実行し、検出結果として出力される画像ファイルやログファイルを基にモデルを評価します。
学習・検出実行用サーバー内構成
それでは、サーバー内に物体検出用の環境を作成しましょう。今回構築する構成は以下の通りです。

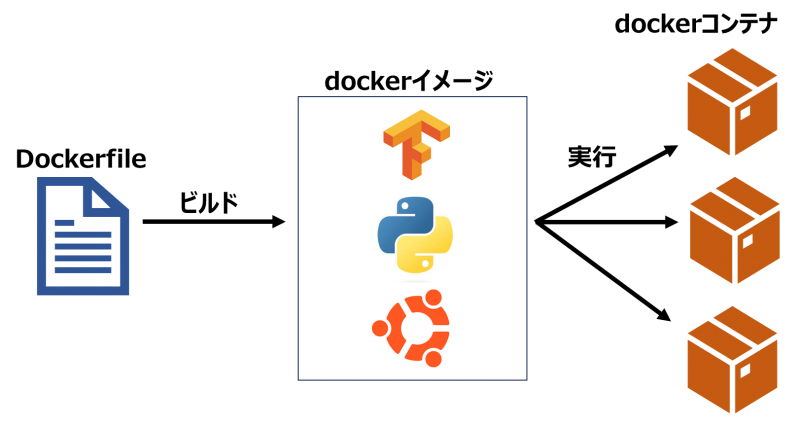
内部の構造や使われているソフトウエアについて、概要を紹介します。
まず、今回はdockerを使って、コンテナと呼ばれる仮想環境を作成します。コンテナ型仮想化の特徴のひとつは、Dockerfileと呼ばれるコードで環境を管理するため、環境の配布が簡単に行えることです。コンテナの作成には、Dockerfileからdockerイメージへのビルド、dockerイメージを基にdockerコンテナの実行を行います。
dockerコンテナからGPUを認識させるため、GPU本体とGPUドライバのほかにNVIDIA Container Toolkitを使用します。導入手順は公式ページをご参照ください。
dockerコンテナ内には、CUDAとcuDNNと呼ばれるソフトウエアを導入します。CUDAはGPUでの計算を最適化するため、cuDNNはディープラーニングの基本的な演算を高速化するためのものです。
そして、Anacondaを導入し、python実行用の仮想環境を構築します。仮想環境の内部には、ソースコードを実行するために必要なパッケージを導入します。主要なものとして、機械学習のソフトウエアライブラリTensorFlowのGPU版であるtensorflow-gpuを導入します。
また、ソースコードやデータはサーバー側に配置されているため、コンテナ側から読み取り可能とするために、コンテナ実行時にはサーバー側のディレクトリをコンテナ側へマウントします。
物体検出用環境構築手順
それでは、サーバー内部に物体検出用の環境構築を行いましょう。まずは、作業用PC上で以下の通りDockerfileを準備します。
# dockerイメージのpull(ubuntu18.04, CUDA11.2.2, cuDNN8.1.1)
FROM nvidia/cuda:11.2.2-cudnn8-devel-ubuntu18.04
SHELL ["/bin/bash", "-c"]
# 前提パッケージ導入
RUN apt-get update ; apt-get install -y vim wget libglib2.0-0 libsm6 libxrender1 libxext-dev
# Anaconda3 2021.05導入
RUN wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh && \
bash Anaconda3-2021.05-Linux-x86_64.sh -b && \
rm -rf Anaconda3-2021.05-Linux-x86_64.sh
ENV PATH $PATH:/root/anaconda3/bin
RUN conda init bash
# Anaconda仮想環境の構築
RUN conda create -n yolov3-tf2 python=3.7
# コンテナログイン時に自動で仮想環境がアクティベートされるようにする
RUN echo "conda activate yolov3-tf2" >> ~/.bashrc
RUN source ~/.bashrc
# 追加パッケージのインストール
SHELL ["conda", "run", "-n", "yolov3-tf2", "/bin/bash", "-c"]
RUN pip list
RUN pip install tensorflow-gpu==2.5.1 && \
pip install opencv-python==4.2.0.32 && \
pip install lxml && \
pip install tqdm
RUN pip list
# yolov3-tf2のソースコード格納用フォルダの作成
WORKDIR /src
上記のDockerfileをサーバーへ転送し、イメージをビルドします。今回は転送先として「/home/yolo-user」ディレクトリを使用します。
# cd /home/yolo-user
# ls -l
合計 4
-rw-r--r-- 1 root root 1809 9月 12 14:16 Dockerfile
# docker build -t yolov3-tf2:latest .
・・・省略・・・
Removing intermediate container 3930f690cef0
---> 0a814730223c
Step 13/13 : WORKDIR /src
---> Running in 16407a7fb838
Removing intermediate container 16407a7fb838
---> ea758d1ef84a
Successfully built ea758d1ef84a
Successfully tagged yolov3-tf2:latest
以上の通り「Successfully tagged yolov3-tf2:latest」が最後に出力されたら成功です。dockerイメージが作成されていることを確認します。
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
yolov3-tf2 latest ea758d1ef84a 12 minutes ago 12.9GB
次は、今回使用するYOLO3実行用のソースコードを、GitHubからzip形式でダウンロードします。今回は下記リンクにある「yolov3-tf2」を使用します。
ダウンロードしたzipファイルをサーバーへ転送し、zipファイルの解凍を行います。今回は転送先としてDockerfileと同様「/home/yolo-user」ディレクトリを使用します。解凍後、yolov3-tf2-masterディレクトリが存在していることを確認します。
# cd /home/yolo-user
# unzip yolov3-tf2-master.zip
・・・省略・・・
# ls -l
合計 4096
-rw-r--r-- 1 root root 1809 9月 12 14:16 Dockerfile
drwxr-xr-x 7 root root 4096 12月 16 2022 yolov3-tf2-master
-rw-r--r-- 1 root root 4184117 9月 12 14:20 yolov3-tf2-master.zip
続いて、コンテナの実行を行います。
# docker run --name yolov3-tf2-container --gpus all --rm -d -it -v /home/yolo-user/yolov3-tf2-master:/src yolov3-tf2:latest
a40fed70f9f596b84d5e93e9c0c3453cb0ee5133c1df2d1c73cbdfce0ab8418c
「docker run」コマンドの中で「–gpus all」オプションを指定し、コンテナとGPUを連携します。また、「-v /home/yolo-user/yolov3-tf2-master:/src」オプションで、サーバー側の「/home/yolo-user/yolov3-tf2-master」ディレクトリを、コンテナ側の「/src」ディレクトリへマウントします。
その後、dockerコンテナが起動しているか確認します。
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a40fed70f9f5 yolov3-tf2:latest "bash" 3 seconds ago Up 2 seconds yolov3-tf2-container
以上で、環境構築は完了です。それでは、実際にコンテナを使ってみましょう。「docker exec」コマンドを使用してコンテナ内部にログインします。コンテナIDとして、「docker ps」コマンドで確認したものを使用します。
コンテナにログイン後、「nvidia-smi」コマンドを使用して、コンテナ内部からGPUが認識できているかどうか確認します。
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a40fed70f9f5 yolov3-tf2:latest "bash" 3 seconds ago Up 2 seconds yolov3-tf2-container
# docker exec -it a40fed70f9f5 /bin/bash
(yolov3-tf2) root@a40fed70f9f5:/src# nvidia-smi
Tue Sep 12 08:00:50 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.82.00 Driver Version: 470.82.00 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:65:00.0 Off | N/A |
| 0% 40C P8 22W / 350W | 100MiB / 12050MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
また、作業終了後は「exit」コマンドでコンテナからログアウトし、「docker stop」コマンドでコンテナを停止しましょう。
(yolov3-tf2) root@a40fed70f9f5:/src# exit
# docker stop a40fed70f9f5
a40fed70f9f5
# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
おわりに
今回は、麻雀牌検出AIシステムの動作環境構築手順までを説明しました。
次回は、教師データの作成方法とAIにデータを学習させる手順、また、検出を行う手順を説明します。

