
筆者の所属している株式会社BFTでは2023年6月より、十数人の有志により毎月テーマを決めて、コーディングを行っています。その成果物については月に1回開催される開発勉強会で、コードのレビューが行われます。
開発勉強会の目的は下記の通りです。
1.1カ月という短期間である程度実用性のあるコードが書けるようになる
2.参加者のコードをレビューできるようになる
3.複数人で同じテーマのもとコーディングを行うことでモチベーションを保つ
本記事では、Python初心者の筆者が開発勉強会に参加して、実際にプログラミングを行った際に学んだことを紹介します。第2回の開発勉強会のテーマは「某店舗のWebサイトから商品情報を取得する」でした。
※第1回の記事はこちら(PythonのOpenCVでリアルタイム顔検出プログラムを作ってみた【開発勉強会】)です。
目次
PythonでできるWebスクレイピングとは?
Webスクレイピングの概要
Webサイトより必要な情報を抽出する技術のことをWebスクレイピングと言います。Webスクレイピングにより、抽出した情報を用いて分析することや、膨大な情報の中から必要な情報を抽出することができます。
スクレイピングと似た言葉にクローリングという言葉がありますが、スクレイピングはWebサイトからの情報抽出を指すのに対し、クローリングはWebサイトを巡回することを指します。
Webスクレイピングを行う際は、ほとんどの場合において特定のWebサイトをターゲットにするため、そのWebサイトの構造(ページのソース)をよく調べる必要があります。
Webスクレイピングを実施するうえでの注意点
・サーバに負担をかけないようスリープ処理を入れる
Webスクレイピングではプログラムの繰り返し処理などにより、Webサイトへ高速かつ大量のアクセスを行う場合があります。このような、サーバに負担をかけると考えられる処理を行う場合は数秒程度のスリープ処理を挟む必要があります。
・規約でWebスクレイピングを禁止しているサイトには実施しない
Webサイトによっては規約でWebスクレイピングを禁止しているものもあります。Webスクレイピングを行う際は、必ずWebスクレイピングを行いたいサイトの規約を確認してから実施するようにしましょう。
ほとんどのWebサイトでは、Webスクレイピングを禁止しているかどうかは、ブラウザにて「[WebサイトのURL]/robots.txt」を確認することで判断できます。robots.txtのUser-agentにWebスクレイピング禁止もしくは許可の対象となるクローラ名、DisallowにWebスクレイピングが禁止されているURLもしくはディレクトリが書かれています。「User-agent: *」と書かれている場合はすべてのクローラが対象となります。「Disallow: /」と書かれている場合はWebサイト全体がWebスクレイピング禁止となります。
Webスクレイピングに利用されるライブラリSelenium
Webスクレイピングに使えるPythonのライブラリはいくつかありますが、ここではSeleniumについて解説します。
Seleniumとは?
SeleniumはWebDriverを介してブラウザを自動で操作します。人がブラウザを操作する動きを実現することができるため、他のWebスクレイピングに使えるライブラリと比較して、ブラウザ上でログインやボタンのクリックなどの複雑な操作が行えます。
Seleniumの使い方
Seleniumを使用する際は下記コマンドでインストールします。
> pip install selenium
WebDriverも必要となるため、下記コマンドでインストールします。下記コマンドはGoogle Chromeを使うことを前提としています。他のブラウザを使う場合は、そのブラウザに合ったWebDriverをインストールします。
> pip install chromedriver-binary
Pythonで下記のように記載してWebDriverを読み込みます。
driver = webdriver.Chrome(options=options)
※optionsは事前に「–headless」など、必要なものを指定しておきます。
下記のように記載してブラウザを開き、操作を行います。
driver.get(“[Webスクレイピングを行いたいWebサイトのURL]”)
※操作に関しては後述の「今回一番評価されたプログラムの紹介 > プログラムの処理内容」で解説します。
操作が終了したら、下記でブラウザを閉じます。
driver.quit()
今回一番評価されたプログラムの紹介
開発勉強会では毎回投票でその月の一番良かったプログラムを決めています。ここでは今回の開発勉強会で一番評価されたプログラムを紹介します。
今回選ばれたプログラムは下記の点において評価されました。
・カテゴリーを選択し、そのカテゴリーに該当する商品名を出すという流れとなっており、実際にメニューを見て商品を選ぶというシチュエーションに近い。
・先に商品一覧を取得しているため、ユーザが入力後のレスポンスが早い。
・プログラムに書かれているURLが最低限のものだけである。
・商品情報が含まれるURLすべてから商品情報を取得するプログラムと比較して、複数のカテゴリーに属する商品情報が重複して出力されない。
・ログレベルを3にすることでSeleniumの警告、エラー以外の出力が出ないようにしている。
実装環境
・Python 3.11.4
・selenium 4.11.2
・chromedriver-binary 116.0.5845.96.0
・Google Chome 116.0.5845.188
※chromedriver-binaryのバージョンは、Google Chromeのバージョンと一致するようにしてください。バージョンが異なる場合、プログラム実行時にエラーが出ることがあります。
プログラムの処理内容
プログラム実行後Webスクレイピングでカテゴリーと商品情報を取得し、カテゴリー一覧を出力します。商品のカテゴリーを選ぶと、選んだカテゴリーの商品名を出力します。
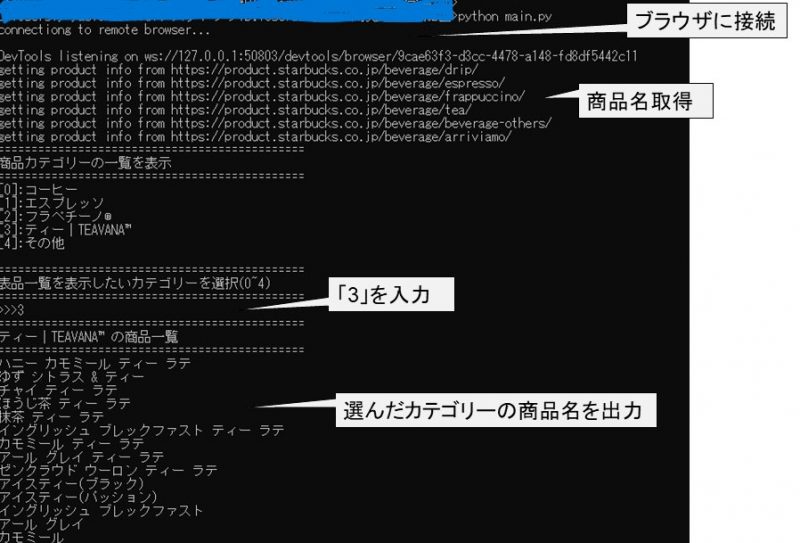
Webスクレイピングを行っている箇所は下記のような記述となっています。
<WebDriverの初期化>
from selenium import webdriver
from selenium.webdriver.chrome.webdriver import WebDriver
from selenium.webdriver.remote.webelement import WebElement
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def init_driver() -> WebDriver:
_options = webdriver.ChromeOptions()
_options.add_argument(‘–headless’)
_options.add_argument(‘–log-level=3’)
print(‘connectiong to remote browser…’)
return webdriver.Chrome(options=_options)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
driver = init_driver()
optionsを指定することで、プログラムを実行した際にブラウザが起動することや、余計な出力が出ることを防いでいます。
<ブラウザへのアクセス>
base_url: Final[str]= “https://product.starbucks.co.jp/beverage/”
driver.get(base_url)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
driver.quit()
<情報の取得>
from selenium.webdriver.common.by import By
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
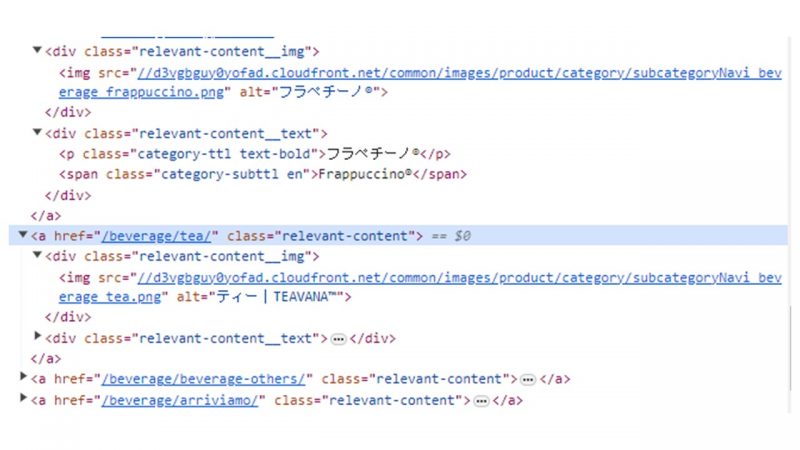
category_xpath: Final[str] = “//a[@class=’relevant-content’]”
a_elmnts = driver.find_elements(by=By.XPATH, value=category_xpath)
driver.find_elementsにより指定したURLから複数の要素を取得します(取得したい情報が1つの場合は「driver.find_element」を用います)。byには何を用いて要素を取得するかを指定します。By.XPATHと書くことで、XPathを用いて要素を取得できます。valueには取得したい要素が持つ具体的な値を指定します。このプログラムではaタグに含まれる、class名が「relevant-content」であるものの要素(各カテゴリーのURLを含む情報)を取得するように記述しています。後の処理で取得した要素からURLを抽出してアクセスし、カテゴリー名およびそのカテゴリーに含まれる商品名を取得します。
<URLの取得>
# 各カテゴリーのURLを取得
# 例外処理
category_url_tuple = get_category(a_elmnts)
if category_url_tuple is None:
driver.quit()
exit()
# 変数の初期化
category = Category()
category_num = 0
# URL
for _idx, _url in enumerate(category_url_tuple):
if _url is not None:
print(f“getting product info from {_url}“)
ret = get_product_name(_url)
category.set_category_list(ret)
else:
category_num = _idx
情報を取得している箇所の書き方は、Webスクレイピングを行いたいWebサイトのソースに合わせます。
Pythonでプログラムを書いた感想
当時はdriver.find_elementsとdriver.find_elementの違いが分かっておらず、1つの商品名しか取得できなかった点が心残りとなっていました。加えて、aタグの情報を取得しようとするプログラムを書いており、結果として商品情報ではない文字列を取得してしまっていました。翌月もWebスクレイピングを用いるテーマとなっているため、今回の参加者のプログラムから良い点をどんどん取り入れ、まずはその月のテーマを達成できるプログラムが書けるようになりたいと思いました。

