
近年AI(人工知能)はさまざまな進化を遂げてきており、家電製品やChatGPTなどのサービスに活用されています。技術系資格の試験範囲としてAIが含まれたり、AIが搭載された接客ロボットが導入されたり、技術的分野やビジネスの世界でもAIは注目されています。
本記事ではAIの歴史、機械学習、ディープラーニングの解説と画像認識の体験を通してAIに対する知識を身に着けていただこうと思います。
目次
AI(人工知能)と仕事
AI を仕事に役立てようという話をよく聞きます。例えば、製造業では商品のキズなどをAIによる画像認識で判断しています。
他にはコールセンターではAIが話の内容を要約して文章に直してくれたり、ショッピングモールでは案内表示のデジタルサイネージでAIが会話形式で案内してくれたり、と実生活にも浸透してきています。
便利で革新的に思えますが、一方でAIによって人の仕事がなくなるのではないか、という不安が生まれてきます。
このような議論は以前から度々出てきており、今に始まったことではありません。
コンピューターが生まれた当時も、人の力で頑張って計算していたところをコンピューターがやすやすと計算できるようになってしまい、人の力がいらなくなるのではという懸念がありました。しかし、実際はその逆で、現在コンピューターを使った仕事が増えており、コンピューターに仕事を取られるどころかコンピューターを使った仕事が増す結果となりました。
AIも万能という訳ではなく、視覚、聴覚に関してはAIの得意分野ですが、そのほかの感覚(嗅覚、味覚、触覚)については発展途上です。特定分野についてのみ、AIで対応するというのが現状です。

AIの歴史
1946年に出来上がった「ENIAC」 というコンピューターが、AIのはじめとされています。これは世界初の電子式汎用計算機で、高速で複雑な計算を行うことができました。
そこから「パズルや迷路が解ける」というようなことがコンピューターによって可能になってきましたが、この段階では特に実用的なものはありませんでした。
第二次AIブーム(1980~1990年代)では、医者の診断にコンピューターを使うことができるようになってきました。「○○ならば□□である」というような考え方(エキスパートシステム)が、専門性が高い医療の分野などに非常に効果的でした。
しかし、それでもまだ問題はあり、さまざまな事例から知識を集めること自体が大変なことや、知識の定着方法や、定着した知識同士が矛盾していることなど、まだまだ問題点は山積みでした。
実用に向けて以上のような取り組みがあったにもかかわらず、実用化が全く進まなかったため、「AI」と書くだけで嫌われる時期もありました。そこからしばらくAIの限界が感じられ、徐々にAI研究の人気が下火になり、冬の時代に入ります。
そして、現在の第三次AIブームで、画像分析のような「機械学習」や、「ディープラーニング」の研究がされ始めます。今までは「鳥ならばくちばしがある」というような「特徴量」を教える必要がありましたが、調べたいものに関する情報(画像や音声など)を大量に読み込ませることによって、コンピューターがそれを学習出来るようになりました。

近年では、前半に述べたような無人レジや、無人で車を運転できるサービスの開発の研究が進んでいます。また「機械学習」や「ディープラーニング」など、個人でも体験できるサービスが展開されています。
例えば、画像を学習させて識別させることが可能な「Teachable Machine」や、文章を自動で生成する「AI writer」のようなものがあります。
このようにAIは飛躍的に進歩して一般に使われるまで浸透しましたが、私たちはこれをどのように使えばよいのでしょう。
AIとは簡単に言えば「知能を持つ機械」なのでそれ単体ではサービスを実現させられません。自分の目的に合った使い方をするために何かを学習させる必要があります。
それではAIを利用するためにはどのようなことをする必要があるのかをこれから見ていきましょう。
AIに学習させるには?
AIを利用したサービスといえば「chat-GPT」のような対話型AI、画像生成AIなどのわかりやすいものだけではなく、天気予報、通販サイトのおすすめ表示、顔認証システムにもAIが組み込まれています。これらのサービスにそれぞれの個性が出るのは、AIの学習方法が違うことが大きな理由です。
AIの学習方法は機械学習が有名であり、その発展形がディープラーニングと呼ばれています。機械学習とディープラーニングでは何を学習するかに大きな違いがあります。
機械学習は「気温」や「購入した商品の値段」などの要素を基に学習を進めて「天気予報」や「通販サイトのおすすめ表示」などを実現します。この場合、学習するデータの特徴を教えてあげる必要があります。
ディープラーニングは「写真」や「録音」などの雑多な情報が入ったデータを基にして、「色や形の傾向」や「声のトーンや大きさの傾向」などを機械が勝手に学習して「画像認識」や「音声認識」を実現します。この場合、人では思いつかない傾向を勝手に学習して分析の精度を高めてくれます。
このように、作るサービスによって学習方法を切り替えなければ思ったようにAIを利用できません。何が得意で何が苦手なのかは学習方法をより詳しく学べば見えてきます。
それでは機械学習とディープラーニングがそれぞれでどのような過程を経て学習されるかを見ていきましょう。
AIの機械学習とは
AIを学ぶうえで初めに出てくるトピックとして機械学習があげられますが、聞いたことがあっても具体的に何かと聞かれればわからないことが多いと思います。
機械学習とは簡単に言うと「人間の学習能力と同様の機能をコンピューターで実現すること」です。
具体的には
- コンピューターに大量のデータを読み込ませて、指定したアルゴリズムを元に特徴を覚えさせる
- 学習した特徴を基にグループ分け、推測、最適化などの判断を自動的に行う
という仕組みになっています。読み込ませるデータや学ばせる特徴をこちらで定義してあげる必要がありますが、事前に設定を組んであげれば勝手に処理を実行してくれます。
そして、機械学習は読み込ませるデータの種類によって
- 教師あり学習
- 教師なし学習
- 強化学習
という3つの種類に分けられます。

教師あり学習
教師あり学習とは、コンピューターに特徴を学習させるデータ(教師データ)を読み込ませて、それを基に未知のデータがその特徴を持っているかどうかを判断させる手法です。
教師データにひもづいた特徴をラベルと呼び、複数のラベルがあればより精度の高い学習をさせることができます。例えば画像から猫を学習させるときに「目が二つある」、「口が一つある」、「耳が二つある」、「尻尾が一本生えている」、「全身に毛皮がある」などのラベルを多く付けて大量の教師データを学習させれば、AIは猫というものをより正確に学習できます。
これによってコンピューターによる分類や予測を行うことができます。
サービスの例を挙げれば顔認識は人間の特徴(色や形、目や口などの部位)を学習することによって実現しています。また、過去の企業売り上げを学習させて今後の売り上げを予測させたり、天候情報を学習させて時期や直近の傾向から明日の天気を予測させたりもできます。
教師なし学習
教師なし学習とは与えられたデータからさまざまな特徴を抽出してその規則性を学習させる手法です。
ここでは明確な正解は与えられず、データの特徴や傾向からコンピューター自身に正解を判断させることができます。これによってクラスタリング(大量のデータをカテゴリーごとに分類してグループ化すること)などが実現できます。
例えば通販サイトでおすすめの商品を表示させたり、SNSで興味のある投稿を表示させたりできます。
強化学習
強化学習とは出力した結果にひもづいた点数を学習させて、どのような行動をとれば最適なのかを判断させる手法です。教師あり学習に少し似ていますが、ここで学ばせるのは「行動」と「報酬」であり試行回数が増えればより精度の高い正解を導くことができます。
アクションゲームでいえば、「コインを手に入れる」、「敵を倒す」、「短い時間でゴールする」などの行動に大きな報酬がもらえるように設定すれば、膨大な試行回数を重ねて最善の行動をとるように学習させることができます。
強化学習は将棋や囲碁などのゲーム用AIに使われていたり、ディープラーニングと組み合わせて自動運転技術などに用いられたりしています。
現在では機械学習の発展形も存在して、有名なものでいえば以下の2つがあります。
- 深層強化学習
- 半教師あり学習
です。
◇深層強化学習
深層強化学習とは従来の強化学習にディープラーニングを組み合わせた学習手法です。
強化学習との大きな違いはニューラルネットワークを利用することであり、報酬を取得するための法則までAI自身が分析して最善の行動をとるように試行回数を重ねることができます。
◇半教師あり学習
半教師あり学習とは教師あり学習と教師なし学習の中間のような学習手法です。具体的には特徴量をインプットする少量のラベルありデータを基にして、大量のラベルなしデータにラベルを付与してより精度の高い教師あり学習に移行できます。
半教師あり学習のメリットは少量のサンプルデータを基にして大量の別データにラベルを付与できて、AIに読み込ませる画像を加工する手間が省けます。
以上のように機械学習が分類され、その組み合わせで現在のAIサービスは形作られています。
AIのディープラーニングとは
AIを学ぶ際、最近はディープラーニングがよく話題にされます。しかしこちらも「何に使われているのか」など具体的なことはよくわからないと思います。それではこれからザックリと学んでいきましょう。
ディープラーニングとは大量のデータをもとにコンピューター自身で特徴を学習していくAI技術です。
機械学習では学ばせる特徴をこちらで指定してあげる必要がありましたが、ディープラーニングは学習の対象を自身で決めて学ぶことができます。
これが実現できる仕組みは、基本的に3層以上からなる多層のニューラルネットワークによって構成されています。
ニューラルネットワークとは人間の神経細胞を模倣したアルゴリズムで、入力されたデータを自動で処理、学習して次の層へ受け渡すものです。3層の内訳については入力層、中間層(隠れ層)、出力層となっていて、中間層は基本的にいくつもの層が折り重なってできています。
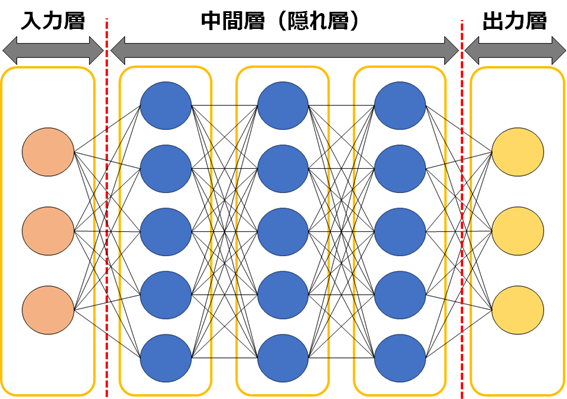
簡単に言えば、このニューラルネットワークの層を潜り抜けるほどにより細かい特徴を学ぶことができます。これによって人間が気にも留めなかった細かい特徴をコンピューターが扱えるようになりました。以前はこの処理にかかる時間も膨大なものでしたが、近年のコンピューターの性能向上により一気に実用化が進みました。
ディープラーニングが活躍するシーンは画像認識、音声認識、自然言語処理が代表的です。
画像認識では、立体検知や個人の顔認証、医療写真の読み込みを行うことで異常のある細胞を検知することまで実現できます。
音声認識では、AlexaやSiriが代表的で話し言葉を正確に聞き取ったり、不鮮明な指示をコンピューター自身が予測して実行したり多彩な活躍ができます。
自然言語処理では、DeepL翻訳が代表的で、文法的に砕けた表現や学術的な単語などを読み取って高品質な翻訳文を生成してくれます。
ディープラーニング自体は複雑な技術ですが、より一般に浸透すればもっと便利な社会を実現できるはずです。
画像認識を体験してみよう
AIサービスの中で画像認識は有名な技術です。
ディープラーニングを利用して画像認識の技術は大きく向上しています。しかし、ディープラーニングが現れる前の機械学習の時代から画像認識は研究されていました。
画像認識は以下のように分類されます。
| 画像認識の種類 | 説明 |
| 物体認識 | ・画像の中の物体を特定する技術 ・色や形などの情報から物体が何であるかを特定します ・自動運転技術において標識や歩行者を検出するために役立ちます |
| 物体検出 | ・画像の中の物体の位置を把握する技術 ・被写体がどこに何人いるのかを奥行きも含めて把握します ・セキュリティカメラの映像から特定個人がどこに向かったか、どのような動きをしているか調査するために役立ちます |
| セグメンテーション | ・画像内の異常を画素ごとに細かく識別する技術 ・医療画像から異常をきたしている細胞がどこからどこまでなのかを判断する場合などに役立ちます |
| 画像キャプション生成 | ・画像の説明を文章で出力する技術 ・動画編集アプリの便利機能などで使われるほか、画像生成AIなどもこの技術の応用で作られています |
| 顔認識 | ・人間の顔を認識して特定する技術 ・自身の顔を登録してセキュリティロックをかけたり、顔の特徴を覚えさせて表情から感情を予測させたりすることに使われています |
| 文字認識 | ・画像に写る数字や文字を識別する技術 ・手書きの文字や印刷された文字を検出してデータに変換できます |
画像認識は基本的に「AIが物体の特徴を学習して画像を解析する」という仕組みであり、簡単な分類は機械学習で実現できます。詳細な特徴を自ら学習するディープラーニングを取り入れると、より正確な判断を下せるように進化しています。
それでは、画像認識の流れをわかりやすく見ていきましょう。
今回はTeachable Machineというツールを使って実際に物体認識の画像認識を行ってみました。Teachable MachineはGoogleが提供している機械学習ツールです。
サイトにアクセスしたら「使ってみる」をクリックしましょう。
画像認識を行うため、「画像プロジェクト」をクリックします。
それでは例としてじゃんけんを利用し、「グー」、「チョキ」、「パー」を機械に覚えさせてみます。
Teachable Machineは画面左の「Class」に大量の学習用データ(今回は写真)を入れ、画面中央の「トレーニング」で各「Class」の学習を行い、最後の「プレビュー」欄で読み込んだ画像が左の「Class」で言うとどの項目に該当するかを判断してくれる、という仕組みです。
初めに、「グー」「チョキ」「パー」の学習を行います。
連続撮影を使ってそれぞれの形をした手を100枚近く撮影しましょう。
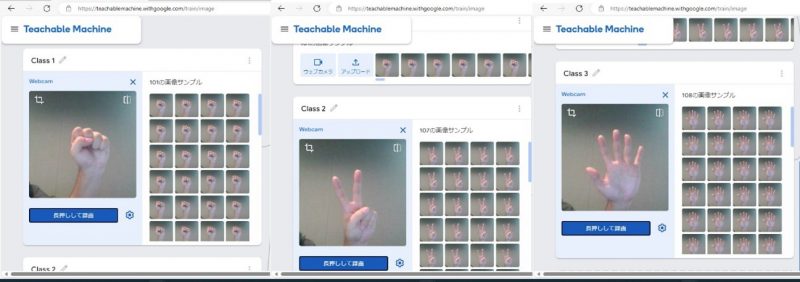
大量の画像を撮影したことにより、「グー」と「チョキ」と「バー」のデータを取得しました。
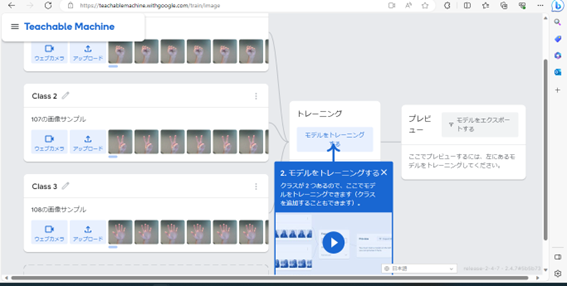
このデータを使い、トレーニングを行います。このトレーニングにより、「グー」と「チョキ」と「パー」とはどういったものかを学ばせることができました。
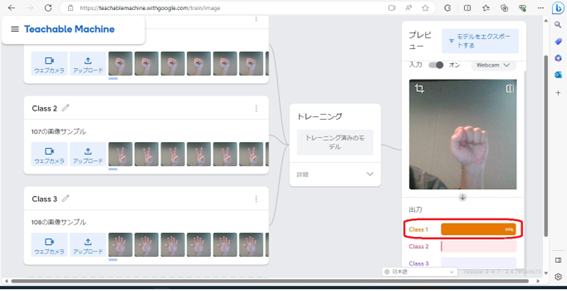
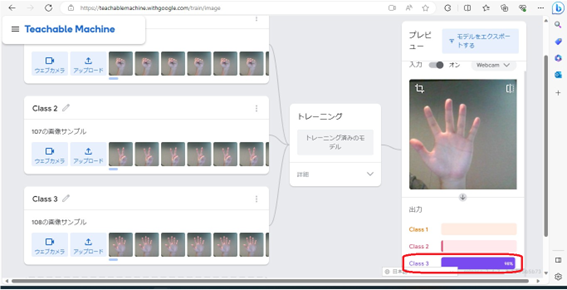
今回はClass1をグー、Class2をチョキ、Class3をパーとしました。次に、自分の手の形を見せて、どの形に見えるか判断させます。
初めにグーの形を見せました。そうしたところ、Class1(グー)であると判断してくれました。
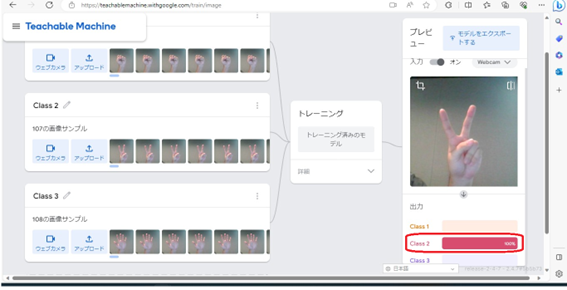
チョキとパーも同じく、チョキの場合はClass2(チョキ)、パーの場合はClass3(パー)という結果になりました。
もちろん、全く関係ない形を出すとどれにも該当しませんでした。
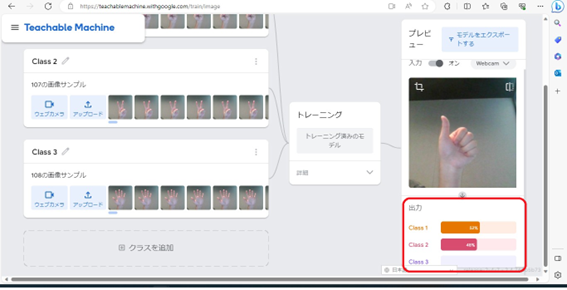
このように、グー、チョキ、パーの画像を大量に読み込ませさえすれば、「グーは指を0本、チョキは指を2本、パーは指を5本立てている状態です」といった指示をせずとも、今カメラに写っているものはどの形を示しているかを認識してくれることがわかりました。
このツールを利用することにより、プログラミングを一から組まずとも、画像の判定を行うことができます。
まとめ
画像認識の体験を通して大量に画像を読み込んだだけでここまで精度の高い学習ができることには驚きました。AIは特に「この手の形は何本指を立てている」とこちらから明示せずとも、画像のみから判断ができるところまで成長しています。近年は対話型AIなど、身近にAIの存在が来ていますが、まだまだ知らない使い方があるのだと痛感しました。
最後に、これからは、コンピューターが現れた時もそうだったように、仕事が奪われる可能性に目を向けるのではなく、新たな仕事ができる可能性に目を向け、新しい技術に注視し続けたいと思います。

